


根据微软官方介绍,Maia 200 作为一款强大的 AI 推理加速器,旨在显著改善 AI token 生成的经济性。
Maia 200 基于台积电的 3 纳米工艺打造,配备原生 FP8/FP4 张量核心、重新设计的内存系统,拥有 216GB HBM3e 内存、7TB/s 带宽以及 272MB 片上 SRAM,并配有数据传输引擎,从而能够保证大规模模型高效、快速地进行数据流动。
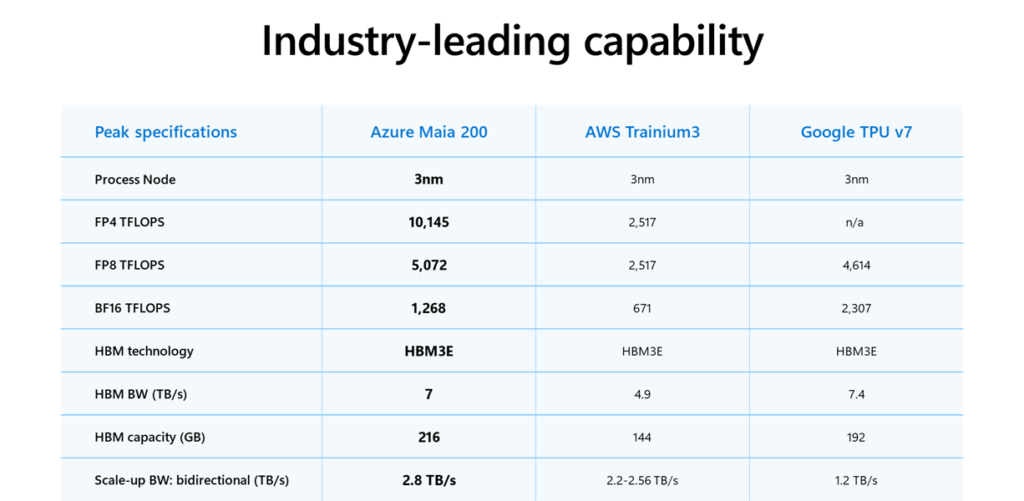
这些使得 Maia 200 成为任何超级计算平台中表现最强的第一方硅片,其 FP4 性能是第三代 Amazon Trainium 的三倍,FP8 性能超越了谷歌第七代 TPU。
与此同时,Maia 200 还是微软迄今为止最高效的推理系统,每美元性能比该公司当前集群中的最新一代硬件提升了 30%。
Maia 200 专为低精度大模型设计:
-
每颗芯片在 FP4 精度下可提供超过 10 PFLOPS 的算力
-
在 FP8 精度下可提供超过 5 PFLOPS 的算力
-
SoC 热设计功耗(TDP)为 750W
在实际应用中,Maia 200 可以轻松运行当前规模最大的模型,并为未来更大规模模型预留充足空间。

至关重要的是,FLOPS(浮点运算次数)并非提升人工智能速度的唯一要素,数据输入同样重要。Maia 200 通过重新设计的内存子系统解决了这一瓶颈问题。Maia 200 的内存子系统以窄精度数据类型、专用 DMA 引擎、片上 SRAM 和用于高带宽数据传输的专用片上网络 (NoC) 架构为核心,从而提高了令牌吞吐量。
优化的人工智能系统
在系统层面,Maia 200 引入了一种基于标准以太网的新型双层可扩展网络设计。定制的传输层和紧密集成的网卡无需依赖专有架构,即可实现卓越的性能、强大的可靠性和显著的成本优势。
每个加速器都会暴露:
-
2.8 TB/s 双向专用扩展带宽 -
可预测的、高性能的跨集群集体操作,最多可达 6,144 个加速器
该架构可为密集推理集群提供可扩展的性能,同时降低 Azure 全球集群的功耗和总体拥有成本。
每个托架内,四个 Maia 加速器通过直接的非交换链路完全连接,从而实现高带宽的本地通信,以获得最佳推理效率。机架内和机架间联网均采用相同的通信协议,即 Maia AI 传输协议,从而能够以最小的网络跳数实现跨节点、机架和加速器集群的无缝扩展。这种统一的架构简化了编程,提高了工作负载的灵活性,并减少了闲置容量,同时在云规模下保持了一致的性能和成本效益。

资料来源:https://blogs.microsoft.com/blog/2026/01/26/maia-200-the-ai-accelerator-built-for-inference/
艾邦建有服务器液冷散热交流群,聚焦服务器液冷技术前沿,涵盖冷板/浸没/喷淋式方案设计、材料升级(耐腐蚀管路、密封件创新)、CDU运维与能效优化、政策标准解读(PUE、OCP规范)等。欢迎大家加入我们,共绘服务器液冷散热未来!


报名方式:
方式1:请加微信并发名片报名
电话:Elaine:13418617872(同微信)
邮箱:ab052@aibang.com

扫码添加微信,咨询会议详情
注意:每位参会者均需提供信息
方式2:长按二维码扫码在线登记报名

或者复制网址到浏览器后,微信注册报名:
https://www.aibang360.com/m/100283?ref=172672
微信扫描下方的二维码阅读本文
- 热交换核心 :冷板(CPU/GPU专用)、CDU(冷量分配单元);
- 循环网络 :Manifold分液器、EPDM/PTFE管路、快接头;
- 动力与控制 :变频循环泵(如飞龙股份电子泵)、智能温控系统。
